平均数不够用:为什么还要看中位数和标准差
同一个平均值,可能藏着完全不同的现实。想真正看懂一组数据, 你至少需要知道两个问题:中心在哪里,以及数据散得有多开。
先做个小测验
假设有一间很小的公司,一共 10 个人。 其中 9 个普通员工,每月工资 5000 元;还有 1 个老板,每月给自己开 50 万。
现在有人问你:
“这家公司平均工资多少?”
我们算一下:
(5000 × 9 + 500000) ÷ 10 = 54500
于是这家公司可以骄傲地宣布:
我们员工平均月薪 5 万 4。
但你品一品——这家公司真的有人挣 5 万 4 吗?
没有。
9 个人挣 5000,1 个人挣 50 万。没有任何一个人的工资,接近这个“平均数”。
这就是今天我们要聊的第一件事:
平均数很有用,但它不是永远可靠。

平均数:最熟悉,也最容易被误用
平均数,也叫 Mean。我们从小学就会算:
把所有数加起来,再除以个数。
它太常见了,常见到我们几乎忘了问一句:
它到底在描述什么?
你可以把平均数想象成一组数据的“重心”。 如果每个数据都是跷跷板上的一个小球,平均数就是让跷跷板保持平衡的那个支点。
大多数时候,平均数很好用。
比如一个班的考试成绩,大家都在 60 到 95 分之间,没有特别离谱的分数。 这时候说“平均分 78”,通常可以大致代表整体水平。
但问题出在哪儿?
出在那个老板的 50 万上。
平均数有一个明显弱点:
它对极端值特别敏感。
只要有一个数据特别大,或者特别小,它就能把整个平均数拉过去, 拉到一个和大多数人都不太接近的位置。
这就是为什么工资、房价、财富、城市收入这类数据里, “平均值”经常会让普通人感觉不真实。
不是因为平均数算错了,而是因为:
平均数描述的是数学重心,不一定描述大多数人的真实处境。
中位数:那个更老实的家伙
那遇到这种情况怎么办?
统计学里还有另一个非常重要的中心指标:
中位数 Median。
中位数的算法特别朴素:
把所有数从小到大排好队,站在最中间的那个数,就是中位数。
我们回到那家公司。
10 个人的工资从小到大排,是这样:
10 个数,最中间是第 5 和第 6 个。它们都是 5000,所以中位数还是 5000。
中位数 = 5000 元。
你看,这个数字是不是诚实多了?
它告诉你:这家公司里,一个普通员工,大概就是这个水平。

中位数最大的优点是:
它不容易被极端值带偏。
那个老板就算给自己开 500 万、5000 万,只要其他 9 个人还是 5000, 中位数依然基本不动。
因为中位数只关心“排在中间的是谁”,不关心最两端的数字到底有多夸张。
什么时候应该看中位数?
这里给一个很实用的判断方法。
如果一组数据比较均匀,没有特别离谱的极端值,平均数通常很好用。
比如:
- 一次普通考试的班级成绩
- 一群年龄相近学生的身高
- 一周每天的正常气温
这些数据大多不会出现一个值比其他值大几十倍、几百倍。 这时候平均数通常能代表整体情况。
但如果数据里很可能存在极端值,或者分布非常不均匀, 你就应该主动看中位数。
比如:
- 工资收入
- 房价
- 财富分布
- 城市人口规模
- 视频播放量
- 社交媒体粉丝数
这些数据经常会出现少数特别大的值。 一个顶级主播、一个超级富豪、一套天价豪宅,都可能把平均数拉得很远。
所以下次再看到“某地平均工资 1 万 5”这种说法,你可以多问一句:
那中位数是多少?
这句话往往比直接相信平均数更接近真实生活。
等等,光知道“中间在哪”还不够
到这里,我们已经能找到一组数据的中心了。
这个中心可以是平均数,也可以是中位数。
但我要告诉你一件事:
只知道中心,远远不够。
看下面两个班的数学成绩。
78, 80, 82, 79, 81
50, 95, 60, 100, 95
你算一下平均分:
- A 班平均分 = 80
- B 班平均分 = 80
两个班平均分一模一样,都是 80。
那这两个班的情况一样吗?
完全不一样。
A 班所有人都在 80 分上下,整整齐齐,说明全班水平很稳定。
B 班呢?
有人考 50,有人考 100,差距非常大,说明班里两极分化明显。
如果你只看平均分,你会以为这两个班一样。 但实际上,它们的内部结构完全不同。

那我们要怎么描述这种“散开的程度”?
这就要请出今天最后两个主角:
方差 Variance 和 标准差 Standard Deviation。
方差和标准差:描述波动的尺子
方差和标准差听起来有点吓人,但本质很简单。
它们衡量的是:这组数据到底散得有多开。
如果所有数据都挤在平均值附近,波动就小,标准差也小。
如果数据散得到处都是,波动就大,标准差也大。
所以你可以先把标准差理解成一把尺子:
标准差,是测量“数据通常离平均值有多远”的尺子。
A 班成绩都在 80 分附近,所以标准差小。
B 班成绩从 50 到 100 都有,所以标准差大。
这里不用急着背公式。先记住它的直觉意义就够了:
- 标准差越小,数据越整齐、越稳定、越可预测。
- 标准差越大,数据越分散、越波动、越不稳定。
那方差和标准差有什么区别?
方差和标准差都在描述波动。
区别在于,方差用的是“平方后的距离”,所以它的单位不太直观。
比如成绩的单位是“分”,但方差的单位会变成“平方分”。 工资的单位是“元”,但方差的单位会变成“平方元”。
这听起来就很奇怪,也不太适合日常解释。
标准差则会把单位拉回到原始数据的单位。
- 成绩的标准差,单位还是“分”。
- 工资的标准差,单位还是“元”。
- 气温的标准差,单位还是“℃”。
所以在日常理解里,标准差通常比方差更容易解释。
你可以这么记:
方差是计算波动的中间语言,标准差是更适合人类理解的版本。
为什么标准差这么重要?
这是我最想强调的一点。
我们的大脑天生喜欢一个数字。
平均分、平均工资、平均寿命、平均收益——简单、好记、好比较。
所以平均数特别受欢迎。
但只看平均数,你会错过一大块信息。
那块信息,就是波动。
标准差告诉你的,不是“中心在哪里”,而是:
这组数据到底稳不稳定。
举几个生活里的例子。
选地方生活
两个城市年平均气温都是 20℃。
听起来一样舒服,对吧?
但 A 城常年在 18℃ 到 22℃ 之间,天气很稳定。
B 城夏天 40℃,冬天 -5℃,一年里冷热变化巨大。
平均气温一样,但住起来完全不是一回事。
这里真正影响体验的,就是波动。
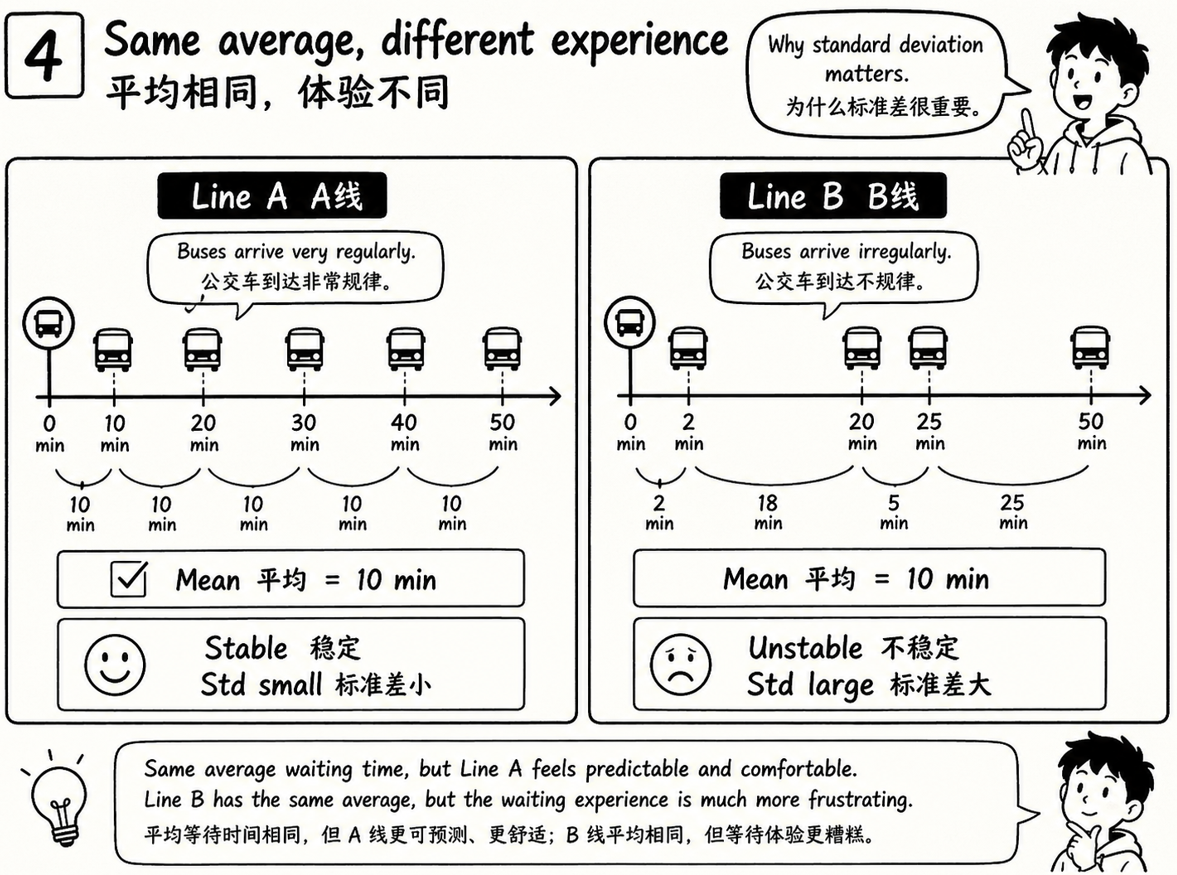
等公交车
两条公交线路,官方都说平均 10 分钟一班。
A 线真的差不多每 10 分钟来一辆。
B 线有时候 2 分钟来三辆,有时候等 25 分钟都不来。
平均值一样,但等待体验完全不同。
A 线标准差小,所以稳定。
B 线标准差大,所以让人抓狂。
投资收益
两个基金过去五年平均收益都是 8%。
A 基金每年大概都在 7% 到 9%。
B 基金今年 +40%,明年 -25%,后年又突然暴涨。
平均收益一样,但风险完全不同。
这就是为什么专业投资人不会只看平均收益,也会看波动。
把今天的内容串起来
我们今天聊了四个词:
如果让我用一句话总结今天的全部内容,那就是:
一组数据的真相,至少需要两个数字才能描述: 一个告诉你“中心在哪”,一个告诉你“散得多开”。
平均数和中位数,帮你理解中心。
标准差,帮你理解波动。
只看其中一个,你看到的通常只是半个故事。
最后再啰嗦一句
回到开头那家公司。
如果有人只告诉你“平均工资 5 万 4”,你现在应该会本能地多问一句:
中位数是多少?标准差大不大?
这种“多问一句”的本能,就是数据素养的开始。
在这个被数据包围的时代,谁都能甩给你一个漂亮的平均数。
但能不能看穿它背后藏着什么、漏掉了什么—— 这才是把数据真正变成判断力的关键。
下次再有人用一个“平均数”想说服你什么,记得在心里提醒自己:
平均数只是故事的开头,不是结尾。
发表回复