数据也有“长相”:聊聊分布、偏态和钟形曲线
拿到一堆数字,别急着算平均。先画出来看看,它到底长什么样。 数据的形状,会告诉你应该用什么方式去理解它。
先回顾一下我们聊到哪了
如果你看过前两篇——
第一篇,我们学会了分辨数据类型:连续型和离散型。
连续型数据可以不断细分,比如身高、体重、温度。 离散型数据只能一个一个数,比如人数、次数、件数。
第二篇,我们学会了描述一组数据的中心和波动。
中心可以用平均数,也可以用中位数。 波动可以用方差和标准差来理解。
今天我们往前再走一步,问一个更有意思的问题:
当你把一大堆数据画出来,它们会呈现出什么“形状”?
这个“形状”,就叫:
数据分布 Data Distribution。
听起来有点抽象,但其实你每天都在和它打交道。 只是很多时候,我们没有把它画出来而已。
数据其实是有“长相”的
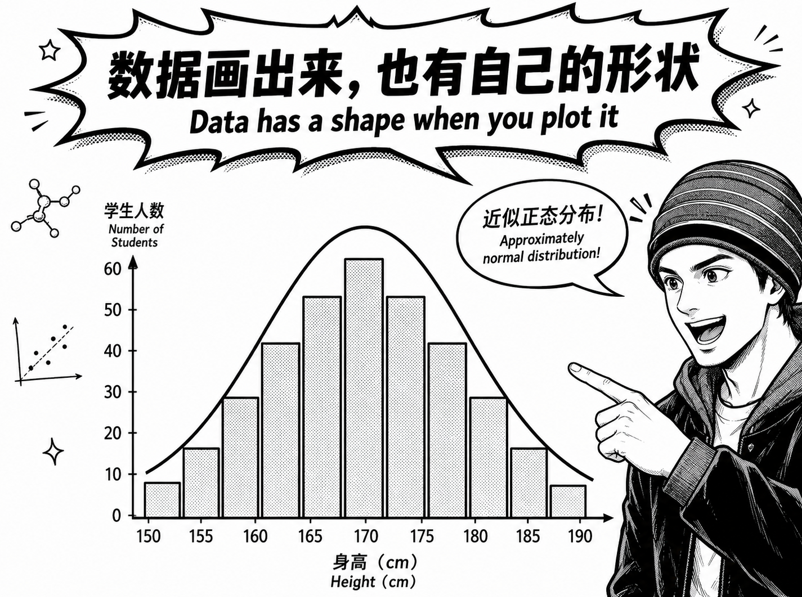
想象一下,你测量了全校 1000 个同学的身高。
然后你做一件很简单的事:
把身高每隔 5 厘米分一组,数一数每组有多少人,再画成柱状图。
比如:
- 150–155 cm 有多少人?
- 155–160 cm 有多少人?
- 160–165 cm 有多少人?
- 一直数到 190 cm 以上。
画出来之后,你大概率会看到一个很有意思的形状:
中间高,两边低。
特别矮的人不多。 特别高的人也不多。 大部分人都集中在中间那个“不高不矮”的区间里。
如果你把这些柱子的顶端用一条平滑曲线连起来,就会看到一条很像钟的曲线。
这条曲线,就是统计学里非常重要的:
正态分布 Normal Distribution。
也叫:
高斯分布 Gaussian Distribution。
它可能是整个统计学里最有名的一条曲线。
为什么正态分布这么常见?
正态分布重要,是因为很多连续型数据都容易长成这个样子。
比如:
- 同龄人的身高
- 同龄人的体重
- 一片麦田里每株麦子的高度
- 一个人每天的睡眠时长
- 很多大样本考试的分数
这些数据画出来,常常会接近那种“中间多、两头少”的钟形。
这不是巧合。
背后有一个很重要的统计学规律,叫:
中心极限定理 Central Limit Theorem。
名字听起来很吓人,但你先不用记公式。
你只需要记住一个直觉:
当一个结果是由很多个微小、独立、随机的因素一起影响时,它最后往往会接近钟形分布。
拿身高举例。
一个人的身高会受到很多因素影响:
父母基因、小时候的营养、睡眠、运动、激素、成长环境……
每个因素都推一点点。 有的往高处推,有的往低处推。 成百上千个小因素叠加起来,最后就容易形成中间多、两边少的形状。
这就是正态分布为什么经常出现。
它不是“神秘玄学”,而是很多微小随机因素叠加后的自然结果。

正态分布让平均数和标准差变得特别有用
还记得第二篇里讲过的平均数和标准差吗?
平均数告诉你:
数据的中心在哪里。
标准差告诉你:
数据通常离中心有多远。
在正态分布里,这两个数字特别强大。
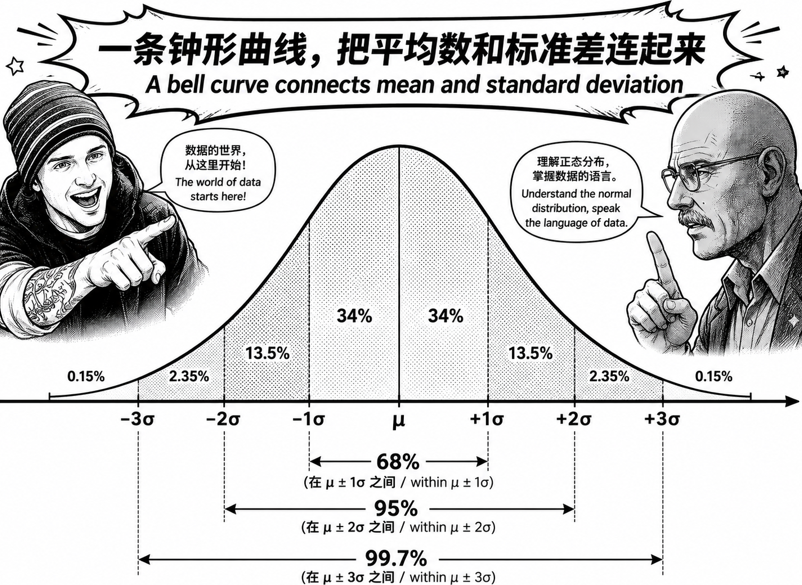
因为正态分布有一个非常经典的规律:
68 – 95 – 99.7 法则。
意思是:
- 大约 68% 的数据,落在“平均数 ± 1 个标准差”之间。
- 大约 95% 的数据,落在“平均数 ± 2 个标准差”之间。
- 大约 99.7% 的数据,落在“平均数 ± 3 个标准差”之间。
这是什么意思?
举个例子。
假设某校男生平均身高是 172 cm,标准差是 6 cm。
那么,如果身高大致符合正态分布:
- 大约 68% 的男生,在 166–178 cm 之间。
- 大约 95% 的男生,在 160–184 cm 之间。
- 绝大多数男生,都会落在 154–190 cm 之间。
如果有一个同学身高 190 cm,那他就已经非常高了。 如果超过 190 cm,就更罕见。
你看,只用了两个数字:
- 平均数 172 cm
- 标准差 6 cm
我们就能大致理解一整群人的身高分布。
这就是正态分布厉害的地方。
当数据接近钟形时,“平均数 + 标准差”就是非常有信息量的一组描述。
但是,不是所有数据都是钟形的
如果世界上的数据都长成钟形,那统计学就简单多了。
可惜,现实没这么乖。
有很多数据根本不是正态分布。
还记得第二篇那个“平均工资 5 万 4”的例子吗?
工资收入就是典型的非正态数据。
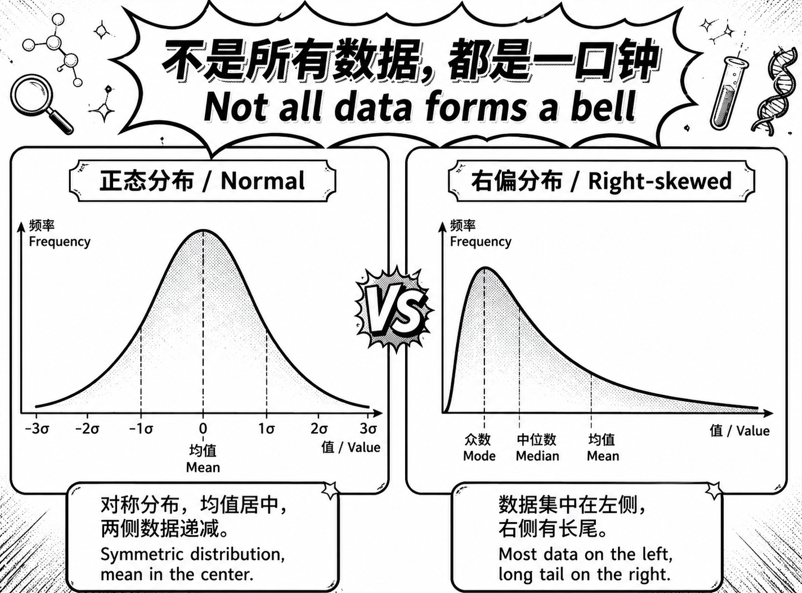
如果你把一个城市所有人的收入画出来,它通常不会是一条左右对称的钟形曲线。
它更可能是这样:
左边一大堆人,集中在中低收入区间。 右边拖着一条长长的尾巴,代表少数高收入和极高收入的人。
这种分布叫:
右偏分布 Right-skewed Distribution。
也可以叫:
长尾分布 Long-tail Distribution。
它的特点是:
大多数数据挤在一边,少数极端值把尾巴拖得很长。
生活里很多数据都是这种形状,比如:
- 收入
- 财富
- 房价
- 视频播放量
- 文章阅读量
- 社交媒体粉丝数
- 城市人口规模
这些数据经常会出现少数特别大的值。
一个超级富豪。 一套天价豪宅。 一个爆款视频。 一个超级大城市。
它们都会把平均数往右边拉。
所以在这种情况下,平均数就容易显得“不接地气”。
不是平均数算错了,而是数据的形状不适合只看平均数。
这时候,更应该看什么?
答案是:
中位数。
中位数不太怕极端值。 它更关心“排在中间的人是谁”,而不是最右边那个极端值有多夸张。
所以:
- 如果数据接近钟形,看平均数和标准差通常很合适。
- 如果数据明显偏向一边、拖着长尾巴,就要多看中位数。
看到分布以后,怎么选指标?
现在我们把前面几篇内容串起来。
拿到一组数据,不要一上来就急着算平均数。
你可以先问三个问题。
第一个问题:
它是连续型数据,还是离散型数据?
第二个问题:
它画出来是对称的,还是偏向一边?
第三个问题:
有没有极端值?
如果一组连续型数据画出来接近对称钟形,比如身高、很多自然测量数据,那么:
平均数 + 标准差 往往是很好的描述方式。
如果一组数据明显偏向一边,比如收入、房价、播放量、粉丝数,那么:
中位数 往往比平均数更接近普通人的真实体验。
如果你只看平均数,很可能会被少数极端值带偏。
所以,数据分布的意义不是让你背一个新名词。
它真正的意义是:
帮你判断应该用什么方式理解数据。
这就是为什么统计学里总是强调:
先画图,再分析。
离散型数据也有“分布”
前面讲的身高、体重、收入,大多是连续型数据。
那离散型数据呢?
当然也有分布。
离散型数据不能无限细分,它们通常是在数:
- 发生了几次?
- 成功了几个?
- 出现了多少个?
这里简单认识两个常见名字就够了。
二项分布:成功了几次?
想象你抛硬币 10 次。
你关心的问题是:
出现了几次正面?
可能是 0 次。 也可能是 1 次、2 次、3 次。 最常见的情况,大概会在 5 次左右。
如果你重复这个实验很多很多次,把“10 次里出现几次正面”画成图,就会得到一个分布。
这个分布叫:
二项分布 Binomial Distribution。
它适合描述这类问题:
做 N 次,每次只有两种结果,然后数成功了几次。
比如:
- 抛 10 次硬币,几次正面?
- 投篮 20 次,进了几个?
- 发 100 条短信,几个人回复?
- 做 50 道判断题,答对几道?
二项分布的关键词是:
成功 / 失败。
它不一定非要是真的“成功”,只要每次结果可以分成两类,就可以这样理解。
泊松分布:发生了几次?
还有一种常见的离散型问题,是数:
某件事在一段时间里发生了几次?
比如:
- 奶茶店每小时来几个顾客?
- 一个路口一天发生几次轻微剐蹭?
- 一本书每页有几个错别字?
- 一个客服中心每分钟接到几个电话?
这种情况常常会用到:
泊松分布 Poisson Distribution。
它的关键词是:
单位时间内发生几次。
这里先不用展开公式。
你只要知道,离散型数据也不是乱来的。 它们也有自己的分布规律。
有些是在数“成功几次”。 有些是在数“发生几次”。
以后如果单独讲概率模型,我们再展开二项分布和泊松分布。
现在先记住一点就够了:
连续型数据有连续型的分布,离散型数据也有离散型的分布。
把今天的内容串起来
我们今天认识了一个非常重要的概念:
数据分布。
也就是:
数据画出来之后的形状。
形状不同,理解方式就不同。
如果让我用一句话总结今天的内容,那就是:
拿到一份数据,先别急着算。先把它画出来,看看它长什么样。
因为数据的形状,会告诉你很多事情。
它会告诉你:
- 应该看平均数,还是中位数。
- 应该关注标准差,还是先小心极端值。
- 应该用连续型数据的思路,还是离散型数据的思路。
最后再啰嗦一句
很多人学统计,一上来就背公式、套计算。
但真正有经验的人,拿到数据后通常会先做一件很朴素的事:
画个图看看。
看它是不是一口钟。 看它是不是拖着长尾巴。 看它是不是一格一格的计数。 看它有没有奇怪的异常点。
因为分布的形状里,藏着数据最诚实的样子。
看懂了形状,你就看懂了这份数据的“性格”。
剩下的分析,只是在顺着它的性格,选择合适的工具而已。
所以下次拿到一堆数字,别急着求平均。
先问一句:
它长什么样?
发表回复