判断数据类型,是所有数据分析最容易被忽略、但最关键的第一步。 在按下公式、打开图表、询问 AI 之前,我们先要知道:这一列数据,到底是什么类型?
从两千五百年前的一个想法说起
公元前 6 世纪,古希腊有一位叫毕达哥拉斯(Pythagoras)的哲学家提出了一句话——
“万物皆数。”
他认为,世界的本质不是金、木、水、火,也不是神话里的诸神,而是数字。 音乐的和声背后是数字的比例,宇宙的运行背后是数字的规律,连人的灵魂他都觉得能用数字描述。 当时听起来很离谱,但两千五百年过去了,这句话越来越像是真的。
跳到现代。
埃隆·马斯克(Elon Musk)公开说过:我们生活在“真实世界”里的概率,只有十亿分之一。 他相信我们更可能是某个高级文明计算机里的一段代码。这听起来像科幻片,但他不是随便说的—— 这个观点来自牛津大学哲学教授 Nick Bostrom 2003 年的著名论文《你可能活在一个计算机模拟中》。
这篇论文严肃地论证了一件事:如果世界真的可以被计算机模拟出来,那它的本质就是数据。
不管你信不信这种说法,有一件事是确定的——这个世界上能被我们感知到的一切,几乎都能被数字表达。 你的身高、你的心跳、你正在看的屏幕上的每一个像素、你大脑里正在闪过的念头 (科学家正在用脑机接口把它转成数据)——一切,最终都能变成一串数。
特别是在 AI 的时代,这件事的意义被放大了一万倍。 AI 学不会“美”“善”“勇敢”,但它能学会海量的数据; 只要把这个世界的一切转成数据,AI 就有可能理解它、预测它、甚至重新创造它。
而你想看懂这个数据驱动的新世界,第一步要做的事情,特别简单——
学会判断数据的类型。

一个奇怪的问题
我先问你一个问题。
下面这五样东西——你的身高、你今天喝了几杯水、外面的气温、你考试的分数、你抽到的扑克牌花色—— 它们都是“数据”对吧?你都能用一张表格记下来。
但如果我让你把它们加起来求平均,你会发现:
- 身高的平均,比如 168.5 cm —— 有意义
- 喝水杯数的平均,比如 4.7 杯 —— 好像怪怪的,“4.7 杯水”是什么意思?
- 气温平均,比如 23.6 ℃ —— 有意义
- 分数平均,比如 87 分 —— 有意义
- 花色的平均,红桃 + 黑桃 ÷ 2 = ??? —— 算不出来
为什么有的能算,有的不能算?
因为它们不是同一种数据。
数据的两大类
我知道你可能在课本里看过“定类、定序、定距、定比”这种词,密密麻麻一堆。
我们不那么搞。记住两种就够了:
连续型数据 Continuous
可以测出小数的。
离散型数据 Discrete
只能数数或者分类的。
这听起来很抽象。我们一个一个看。
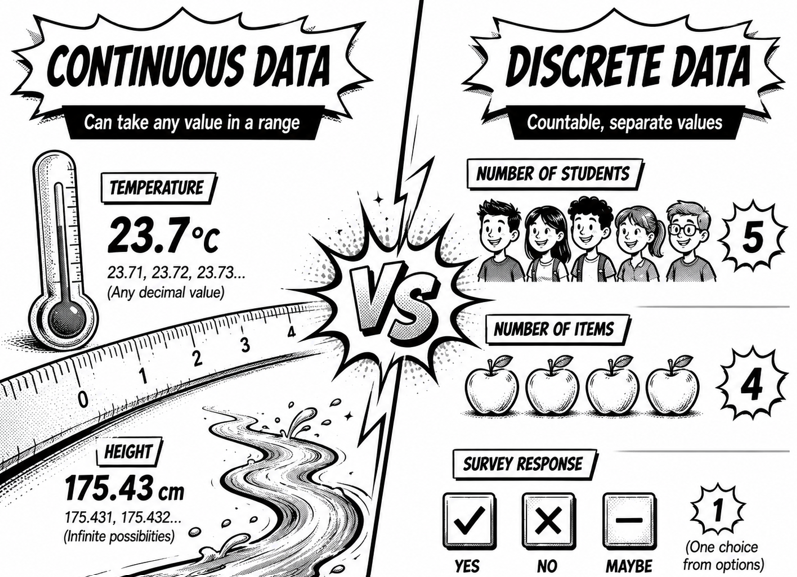
连续型:可以无限切下去的世界
想象你正在量自己的身高。
如果尺子精度是 1 cm,你量出来是 168 cm。 换一把精度 1 mm 的尺子——168.3 cm。 再换一把激光测距仪——168.347 cm。 再换一把更精密的——168.3479 cm。
只要你的工具够精密,168 和 169 之间永远还能塞进无数个数字。 168.5、168.51、168.501、168.5001……理论上没完没了。
这就是连续型数据的本质—— 它在数轴上是一条没有缝隙的线。
生活里常见的连续型数据:
- 身高、体重、腰围
- 气温、水温
- 跑步用了多长时间,包括秒、毫秒
- 从家到学校的距离
- 你睡了多久
- 手机电量百分比,虽然显示是整数,但实际是连续的
判断方法很简单——问自己:这个数据,理论上能不能取到小数?
能。那它就是连续型。

离散型:只能“数”的世界
再换个场景。
你打开一袋彩虹糖,数一下里面有多少颗。 第一颗、第二颗、第三颗……数到最后,47 颗。
会不会出现“这袋有 47.3 颗彩虹糖”?
不会。糖要么是 47 颗,要么是 48 颗,没有半颗。 当然,如果你把一颗咬碎了,那就不是“完整的糖”了。
这就是离散型数据—— 它在数轴上是一个一个分开的点,中间是空的。
生活里常见的离散型数据:
- 班里有几个人
- 你今天发了几条朋友圈
- 掷骰子掷出来的点数:1、2、3、4、5、6,没有 3.5
- 一局游戏里你死了几次
- 抽到几张红桃
判断方法也简单——这个数据,是不是只能“数”出来?
是。那它就是离散型。

那“扑克牌花色”算什么?“游戏角色性别”算什么?
回到开头的问题——花色(红桃、黑桃、方块、梅花)、性别(男、女)、星座(白羊、金牛……)这些东西。
它们看起来根本不是数字。它们是数据吗?是哪种?
答案:都是离散型。
只不过它们穿了个马甲。
“是不是”问题——比如“今天有没有下雨?”(是 / 否)、“这道题做对了吗?”(对 / 错)。 这种只有两个答案的,专门起了个名字叫“二元数据”(Binary)。我们经常把它写成 0 和 1。
“哪一类”问题——比如“你最喜欢哪个季节?”(春 / 夏 / 秋 / 冬)、 “你抽到什么花色?”(红桃 / 黑桃 / 方块 / 梅花)。 这种有几个固定类别的,叫“分类数据”(Category)。
虽然它们看起来不像数字,但本质上都属于离散型—— 因为它们也是“一个一个分开的、中间是空的”。 你不能说“今天下雨度是 0.7”,也不能说“我有一半的红桃”。
只要数据中间没有“无限可分”的特性,它就是离散型。不管它写出来是数字、是文字、还是字母。
为什么这件事这么重要?
讲到这里你可能想问——
OK,我知道身高是连续的,糖果数量是离散的,那又怎么样?
我给你看一个真的会出错的例子。
假设你在统计“班上每个人平均一周看几次电影”。你收了一圈数据:
- 小张:2 次
- 小李:1 次
- 小王:0 次
- 小赵:3 次
- 小钱:1 次
你按 =AVERAGE() 一拉,得出“平均 1.4 次”。
听起来好像没问题。
但 “一周看 1.4 次电影”是什么意思? 没有人能看 0.4 部电影。
你说:“那是平均啊,不是某个人真的看 1.4 次。”
对,用平均值描述一个整体的“中心趋势”是 OK 的——这是统计学允许的简化。
但问题来了:如果你接下来想知道“这个班看电影的习惯波动有多大”—— 比如“是不是有人特别爱看,有人完全不看”?
对连续型数据,比如身高,你算标准差,就能告诉你大家分散得多厉害。
但对离散型数据呢?
如果数据是 0、1、2、3 这种小整数,标准差还能勉强算一下当参考; 但如果数据是“红桃 / 黑桃 / 方块 / 梅花”这种分类呢?
根本算不了标准差。因为这些东西没有“大小”之分——红桃比黑桃“大”多少?没法说。
这时候你需要的是完全不同的一套统计工具,比如比例、卡方检验。 用错工具,得到的结论再漂亮也是错的。
这才是判断数据类型真正的意义—— 它决定了你接下来能用什么方法、不能用什么方法。
一张速查图
为了让你以后不用每次都纠结,给你一个 30 秒决策法:
问自己一个问题:这个数据,理论上能不能取到小数?
✅ 能 → 连续型:可以算平均值、标准差,画折线图。
❌ 不能 → 离散型:要数次数、算比例,画条形图、饼图。
如果数据看起来根本不是数字,比如文字、类别、颜色、是否、对错,直接归到离散型。
就这么简单。
最后再啰嗦一句
以上内容看上去非常简单,但在 AI 的时代里,所有的数据分析,第一步都是这一步。
把“扑克花色”当连续数字平均,把“是不是合格”按温度的方法去算波动, 把“喜欢的季节”画成折线图——这些事情,我见过太多人犯,而且他们自己都意识不到。
毕达哥拉斯说万物皆数,Bostrom 说世界可能是模拟出来的,AI 在用数据重新理解这个世界。 而你和这个数据世界之间的第一道门,就是搞清楚你看到的数据,到底是什么类型。
所以,下次你打开一份数据,别急着按公式。先花 10 秒钟问自己:
我手里这一列,是连续型,还是离散型?
这 10 秒,就是你从“按按钮的人”变成“懂数据的人”的第一步。
发表回复