样本量不是拍脑袋:从一锅汤说起
抽多少样本才靠谱?少了不可信,多了又浪费。样本量不是感觉问题,而是可以被讨论、被计算的问题。
先从一锅汤说起
厨房里有一大锅正在炖的汤。
你想知道这锅汤够不够咸,会怎么做?
不会把整锅汤都喝完。更合理的做法是:先把汤搅一搅,然后舀一小勺尝一口。 只凭这一小勺,你大概就能判断整锅汤的味道。
这件很普通的事,其实藏着统计学里一个非常重要的概念:抽样。
那一小勺汤,就是样本。
整锅汤,就是总体。
你用一小勺的味道,去推断整锅汤的味道。
但问题来了:
那一勺,到底要舀多少才够?
舀太少,比如只沾一滴在舌尖上,可能刚好碰到一粒没化开的盐, 于是你误以为整锅汤都咸得不行。
舀太多,比如喝掉半锅,当然也能判断味道,但这就太浪费了。
所以样本量要解决的问题,不是“抽得越多越好”,而是:
抽多少,才刚好够用?
这就是今天要聊的核心:样本量。
为什么我们非得抽样?
你可能会想:如果想知道整体情况,直接全部检查不就最准了吗?
理论上是这样。现实里,很多时候根本做不到。
第一,全检太贵。
如果有一批几十万、几百万个产品,要每一个都检查,光人力、设备、时间成本就可能高得离谱。
第二,全检太慢。
就算你真的愿意花钱,也不一定等得起。很多时候,产品还要发货,实验还要推进,项目还要做决策, 不可能一直等到“全部检查完”。
第三,有些检查会破坏被检查的东西。
比如你想知道一根火柴能不能划着,最直接的方法就是划一下。但划着以后,这根火柴也就没了。
你不能把一整盒火柴全部划完,然后宣布:“很好,这盒火柴质量合格。”
这听起来像笑话,但很多检测都是类似的:测强度、测寿命、做破坏性实验, 往往都会消耗样品本身。
所以在现实世界里,我们经常只能抽一部分样本,去推断整体情况。
这不是偷懒,而是统计学存在的原因之一。
但前提是:你那一勺要舀得对
说到抽样,很多人第一反应是:“那我抽多少个?”
这个问题当然重要。但在问“抽多少”之前,还有一个更基础的问题:
你从哪里抽?怎么抽?
回到那锅汤。
如果汤已经搅匀了,那么从锅里舀一勺,大概率能代表整锅汤的味道。
但如果汤没有搅匀,盐都沉在锅底,你只从表面舀一勺,可能会觉得味道很淡; 如果你刚好从锅底舀一勺,又可能觉得咸得离谱。
这时候问题不是“勺子太小”,而是样本抽偏了。
现实里也一样。
你想了解全校学生的身高,却只在篮球队门口抽样。
你想了解顾客满意度,却只看愿意主动留言的人。
你想判断一批产品质量,却只拿最上面一层样品。
这些样本即使数量不少,也可能代表不了整体。
所以一定要记住:
样本量解决的是随机波动问题,抽样方式解决的是代表性问题。
如果样本本身是偏的,样本量再大,也只是在更精确地重复一个偏差。
简单说就是:
先别抽偏,再谈抽多少。

抽太少会怎样?一个抛硬币的故事
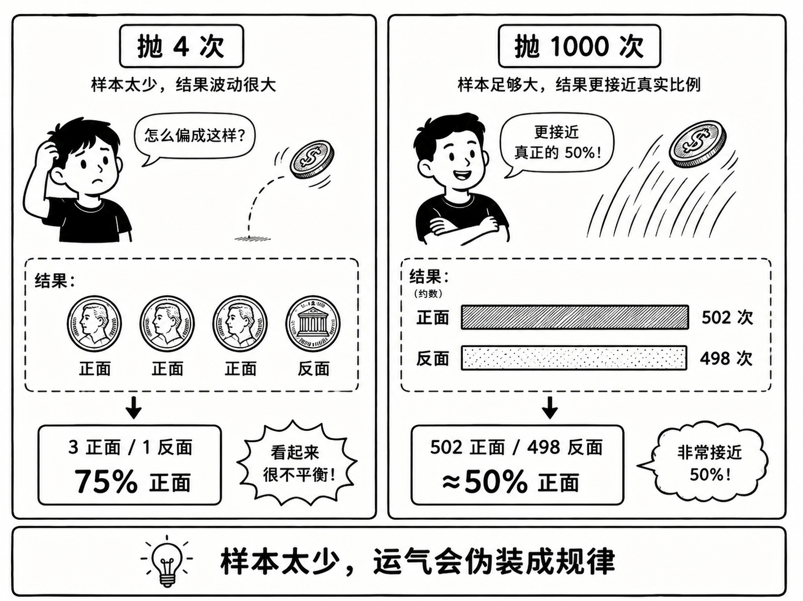
假设你不知道硬币正面朝上的概率是多少,于是想通过实验把它测出来。
你拿起一枚硬币,只抛了 4 次。
结果是:
正、正、正、反
4 次里面有 3 次正面。于是你得出结论:
正面概率是 75%。
这显然不靠谱。
不是硬币真的有 75% 的概率出现正面,而是你抛得太少了。 样本量太小时,运气的影响非常大,几次偶然事件就能把结论带偏。
但如果你抛 1000 次,正面和反面的次数通常会接近一半一半。 算出来的结果就会更接近真实的 50%。
这就是样本量最直观的意义:
样本量太小,结论容易被随机波动带跑偏。样本量越大,结果通常越稳定。
你可以把小样本想象成只看几帧画面就判断整部电影。 可能正好看到打斗场面,就以为这是一部动作片;也可能正好看到哭戏,就以为这是一部悲剧。
看的片段越少,误判的概率越高。
那是不是越多越好?
也不是。
回到那锅汤。你尝一勺就能判断咸淡,没必要喝掉半锅。
样本量增加,确实通常会提高结果的稳定性。但这种提升不是无限线性的。
从 5 个样本增加到 50 个样本,信息量可能提升很明显。
从 5000 个样本增加到 5050 个样本,提升可能就非常有限。
越到后面,你为每一个新增样本付出的成本,可能越来越不划算。
所以样本量的真正智慧,不是“越多越好”,而是找到那个平衡点:
少了不可信,多了不划算。
这也是为什么样本量计算很重要。它不是为了追求一个看起来很大的数字, 而是为了找到一个相对合理的数字。
决定样本量的,不只是总体有多大
很多人第一次接触样本量,会有一个直觉:
总体越大,需要的样本量肯定越大。
比如全国有十几亿人,如果要做一个全国性的调查,是不是必须问几百万人才够?
听起来合理,但在很多统计场景里,并不是这样。
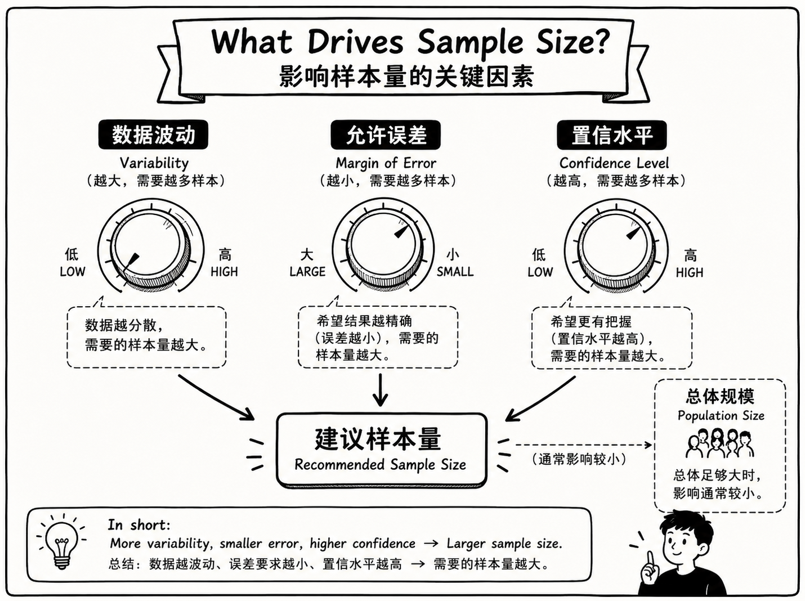
当总体足够大时,真正决定样本量的,通常不是总体本身有多大,而是下面三个因素。
第一,数据本身波动有多大
如果一锅汤已经搅得很均匀,你舀一两勺,大概率就能判断味道。
但如果这锅汤很不均匀,有的地方淡,有的地方咸,那你就需要多尝几勺,而且最好先搅匀。
数据也是一样。
如果一组数据本来就很稳定,样本量可以相对少一些。 如果数据波动很大,样本量就需要更多。
这就和我们前面聊过的标准差有关。
标准差越大,说明数据越分散,你就需要更多样本来把真实情况看清楚。
第二,你想要多准
你只是想判断“这锅汤大概够不够咸”,需要的样本很少。
但如果你要精确判断“还差 0.2 克盐”,那要求就高多了。
统计里也是一样。
你能接受的误差越小,需要的样本量就越大。 你要求越精确,统计上就要付出更多样本成本。
第三,你想要多大把握
你是想“大概有把握”,还是想“非常有把握”?
如果你要求 90% 的把握,样本量可能不算太大。 如果你要求 95%、99% 的把握,样本量通常就会增加。
这就是常说的置信水平。它表达的是:你希望这个结论有多可靠。
所以更准确地说:
在总体足够大的情况下,样本量主要由数据波动、允许误差和置信水平决定,而不是单纯由总体规模决定。
当然,如果总体本身很小,或者你抽样的比例已经非常高,那么总体规模也会产生影响。 这种情况统计上还有专门的修正方法。
但对大多数日常理解来说,先记住这个核心就够了:
不是锅越大就一定要喝越多,而是要看汤搅得匀不匀、你想尝得多准、你想有多大把握。
落到实处:到底该抽多少?
讲到这里,你可能会说:
道理我懂了,但我到底该抽多少?给我个数。
好消息是,这个数是可以计算的。
统计学家早就把“数据波动、允许误差、置信水平”这些因素写进了公式。 你只要明确自己的目标,就能算出一个建议样本量。
坏消息是,那些公式对刚入门的人并不友好。 里面会出现 Z 值、标准差、比例、误差范围、平方项,看起来不太像日常语言。
所以我在本站 Tools 栏目里做了一个简单的样本量计算器。
你不需要先背公式,只要选择一个场景,输入几个关键参数,它就会给出建议样本量, 并说明背后的计算逻辑。
比如:
- 估算一个比例,大概需要多少样本?
- 验证缺陷率是否达到目标,需要抽多少?
- 比较两组连续型数据有没有差异,需要多少样本?
这些问题都不应该靠拍脑袋回答。
下次有人说:
我们抽 50 个差不多吧。
你可以认真问一句:
这个 50 是怎么来的?
因为样本量从来不应该只是一个感觉。它可以被讨论,也可以被计算。
选择场景,输入关键参数,快速得到建议样本量。
把今天的内容收一下
今天我们从一锅汤说起,聊了样本量到底在解决什么问题。
- 第一,抽样是现实需要。 因为全检太贵、太慢,有些检查还会破坏样品。
- 第二,样本要有代表性。 如果抽样方式偏了,样本量再大也可能得出错误结论。
- 第三,样本太少会被随机波动带偏。 就像只抛 4 次硬币,很容易得出一个离谱比例。
- 第四,样本也不是越多越好。 超过某个点之后,增加样本的收益会变小,成本却还在增加。
- 第五,样本量主要受三个因素影响。 数据波动有多大、你想要多准、你想要多大把握。
如果用一句话总结:
抽样就像尝一锅汤。重点不是这锅汤有多大,而是你有没有搅匀、你想尝得多准、你想有多大把握。 把这件事想明白了,就不会再随便拍一个样本数了。
发表回复